

Top Tool: o3-mini
OpenAI released o3-mini, their best AI reasoning model yet; o3-mini reasons on par with the flagship o1 model, but is faster and much cheaper, and comes with a number of useful features for integrating it into AI flows:
OpenAI o3-mini is our first small reasoning model that supports highly requested developer features including function calling(opens in a new window), Structured Outputs(opens in a new window), and developer messages(opens in a new window), making it production-ready out of the gate. Like OpenAI o1-mini and OpenAI o1-preview, o3-mini will support streaming(opens in a new window). Also, developers can choose between three reasoning effort(opens in a new window) options—low, medium, and high—to optimize for their specific use cases.
It's optimized for STEM reasoning, getting stellar benchmark results on CodeForces, GPQA, AIME (2024), and FrontierMath. The o3-mini model is available via API as well as to ChatGPT Plus, Team, and Pro users. Free plan users can try OpenAI o3-mini by selecting ‘Reason’ in the message composer.
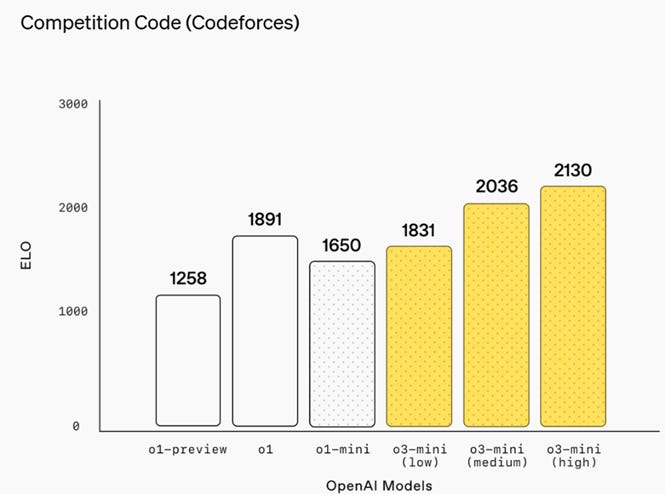
Figure 2. OpenAI o3-mini achieves progressively higher Elo scores with increased reasoning effort, all outperforming o1-mini. o3-mini beats o1’s performance with medium reasoning effort.
OpenAI has released their own Deep Research tool, an agent that synthesizes data and completes multi-step research tasks for you. Depending on the task, Deep Research takes from 5 to 30 minutes to plan, research, and write, and is “powered by a version of the upcoming OpenAI o3 model that’s optimized for web browsing and data analysis.”
OpenAI says Deep Research is for tasks like finance, science, policy, and engineering that need thorough, precise, and reliable research. This is similar to Google’s Deep Research capability. One OpenAI researcher shared how Deep Research provided valuable guidance on treating his wife’s cancer:
We often talk internally at OpenAI about the moments when you “feel the AGI,” and this was one of them. This thing is going to change the world.
They also touted how Deep Research gets a score of 26% on Humanities Last Exam (HLE), the new benchmark that is so hard that all prior AI models before o3 got under 10%.
In a Reddit AMA, OpenAI CEO Sam Altman admitted to ‘being on the wrong side of history’ on open source, and will consider a new open-source strategy for older models. The company also acknowledged the gains of competitors like DeepSeek, and they said they would increase transparency in OpenAI reasoning models:
We’re working on showing a bunch more [model thought process] than we show today — will be very soon.
AI Tech and Product Releases
Mistral announced Mistral Small 3, a 24B parameter open-source model that is competitive with Llama 3.3 70B and Qwen2.5 32B, that Mistral claims “is an excellent open replacement for opaque proprietary models like GPT4o-mini.” Benchmark results confirm Mistral Small 3’s performance and its speed. It can be downloaded from HuggingFace or Ollama and run locally.
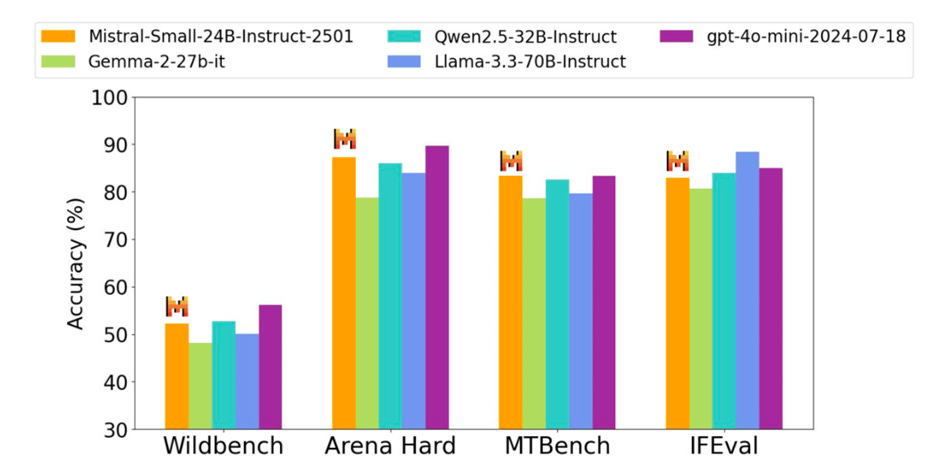
Figure 3. Mistral Small 3 benchmark results are in-line with larger LLMs such as Qwen2.5 32B, Llama3.3 70B and GPT-4o mini.
Mistral has not only released Mistral Small 3 on the Apache 2 license, but they also reaffirmed their commitment to open source in future model releases. Mistral also previewed AI reasoning model releases: “expect small and large Mistral models with boosted reasoning capabilities in the coming weeks.”
AI2 has released Tulu 3 405B, the biggest and best AI model based on fully open post-training recipes to the largest open-weight models. Based on post-training of Llama 3.1 405B, Tulu 3 405B is explained in the blogpost “Scaling the Tülu 3 post-training recipes to surpass the performance of DeepSeek V3.” Among the post-training methods presented, they introduced Reinforcement Learning with Verifiable Rewards (RLVR), a novel method for training LLMs on verifiable tasks such as mathematical problem-solving and instruction following. Overall, Tulu3 405B outperforms prior fine-tunes of Llama 3.1 405B and rivals the performance of GPT-4o.
Perplexity has added DeepSeek-R1 to Perplexity Pro Search as an optional AI model.
Block’s Open-Source Program Office announced Goose, an open-source agentic AI framework that connects AI to real-world actions. Goose by Blocks manages complex autonomous tasks (focused on various engineering domains), runs locally, and allows users to connect Goose to any preferred LLM, external MCP server or API. The open framework also has extensions.
Another open-source project called Browser-use, available on GitHub - is an AI agent similar to OpenAI’s Operator, enabling users to invoke AI automation tasks via a browser use with AI.
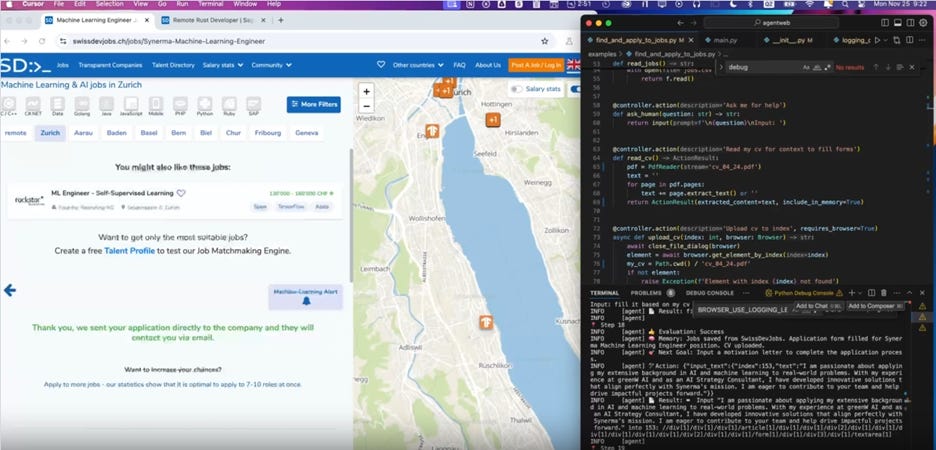
Figure 4. A Browser-use prompt for conducting a job-search: “Read my CV & find ML jobs, save them to a file, and then start applying for them in new tabs, if you need help, ask me.”
The Yue series of open music-generation AI models was released by HKUST and MAP. Yue models come in 1B and 7B sizes and generate music similar to Suno. They are open-source (released under Apache 2 license) and available on HuggingFace and to try out on Fal. The authors shared an abstract and examples at Open Music Foundation Models for Full-Song Generation. The demo results sound good.
MLCommons and Hugging Face have released Unsupervised People’s Speech, one of the world's largest collections of public domain voice recordings for AI research. The dataset contains over a million hours of audio in at least 89 languages and is aimed at advancing speech technology globally.
AI Research News
Our AI research review article for this past week included a number of recent AI model releases:
- VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
- Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
- Baichuan-Omni-1.5: Technical Report
- Qwen2.5 VL vision-language model
- Qwen2.5-1M, long-context model
- Qwen2.5-MAX, a mixture-of-experts (MoE) frontier AI model
- Bespoke-Stratos: The Unreasonable Effectiveness of Reasoning Distillation
The Bespoke-Stratos effort to distill reasoning in smaller LLMs, is the start of a bigger trend, as RL for reasoning scales.
A joint project by DataComp and Bespoke Labs released Open Thoughts, a curated open reasoning dataset of 114k examples, with a goal to distill state of the art small reasoning models. They released Open-Thinker-7B that was developed with this dataset; it surpassed Bespoke-Stratos 7B and came close to DeepSeek 7B distilled model on reasoning-related benchmarks.
AI Business and Policy
As we noted in our article the DeepSeek Meltdown, the DeepSeek R1 release went viral and admiration for the R1 open AI reasoning model evolved into a panic over the rise of scrappy Chinese AI, causing a one-day meltdown in Nvidia and other AI-related stocks.
Chinese AI lab DeepSeek has risen to international fame after its chatbot app topped Apple App Store and Google Play charts. DeepSeek’s efficient AI model training raised questions about the U.S. lead in AI technology, despite facing AI chip export bans from the U.S.
On the heels of the DeepSeek R1 release, numerous US-based companies and government-related entities have blocked DeepSeek AI apps and services due to concerns over potential data leakage to China. The Pentagon has also begun restricting access to DeepSeek amid privacy and security worries.
Google’s X “moonshot factory” graduated Heritable Agriculture, an AI-driven startup aiming to enhance crop production efficiency. Using machine learning to analyze plant genomes, Heritable seeks solutions for sustainable agriculture, addressing issues like water usage and greenhouse gas emissions.
AI systems with ‘unacceptable risk’ are now banned in the EU. As of February 2, the first compliance deadline for the EU’s AI Act has come into effect, prohibiting applications deemed to pose unacceptable risks and subjecting violators to fines up to €35 million or 7% of global revenue. The Act mixes lighter regulatory oversight over limited-risk systems like customer service chatbots with stricter rules for high-risk uses such as healthcare.
OpenAI has utilized the subreddit r/ChangeMyView to assess its AI models’ persuasive capabilities by comparing their responses against human arguments. The company’s latest model, o3-mini, demonstrates strong argumentation skills within the top 80-90th percentile of humans, aiming not for hyper-persuasiveness but to ensure AI doesn't deceive users effectively.
Microsoft is creating a new unit called the Advanced Planning Unit (APU) within its Microsoft AI division to explore societal, health, and work implications of AI. The APU will focus on research and product recommendations related to AI's future impact. Microsoft is continuing to make significant investment in AI, with Q4 2024 capex reaching a record high of $22.6 billion.
Intel is effectively killing Falcon Shores, its next-generation GPU for high-performance computing and AI workloads. The company will instead focus on Jaguar Shores to develop a system-level solution at rack scale for the AI data center market. This shift comes after Intel's Gaudi 3 chip fell short of expectations, failing to meet sales goals due to software issues.
OpenAI may raise up to $40 billion in another fund-raising round, valuing it at $340 billion. The funds are intended for supporting OpenAI’s ongoing financial losses and its Stargate project, which aims to build AI data centers across the U.S.
AI companies are among the notable companies planning or reported to file for IPOs in 2025, in particular Genesys and Cerebras are likely to IPO in 2025.
AI Opinions and Articles
The low-cost to train DeepSeek’s R1 open-source reasoning model has shaken the tech industry. However, Andreessen Horowitz's Anjney Midha argues that AI foundational models will continue to invest heavily in GPUs and data centers for more compute power output.
Dario Amodei shared his own thoughts on DeepSeek R1 and Chinese AI development in a blog post “On DeepSeek and Export Controls.” In it, he calls for continued export controls on AI chips to China, explaining why DeepSeek’s results don’t eliminate the value of such controls.
Regarding DeepSeek’s V3 training, he points out that “historical trend of the cost curve decrease is ~4x per year” so you would expect a lower cost-to-train on better AI models. He puts it this way:
DeepSeek produced a model close to the performance of US models 7-10 months older, for a good deal less cost (but not anywhere near the ratios people have suggested).
He also points out that the RL-based post-training cost-curve for AI reasoning models is at a lower base than LLM pre-training, so scaling gains for reasoning will cost less for now.
Importantly, because this type of RL is new, we are still very early on the scaling curve: the amount spent on the second RL stage is small for all players. Spending $1M instead of $0.1M is enough to get huge gains. … it’s possible for several companies to produce models of this type, as long as they’re starting from a strong pretrained model. Producing R1 given V3 was probably very cheap. We’re therefore at an interesting “crossover point,” where it is temporarily the case that several companies can produce good reasoning models. This will rapidly cease to be true as everyone moves further up the scaling curve on these models. - Dario Amodei
PostScript
Excuse the Late Edition – If you made it this far, thank you. This week’s AI news article was delayed by battling a cold, but we will return to our regular schedule soon. The AI revolution will not be stopped!
"


